Abstract
This project investigates whether linguistic patterns in corporate earnings calls can serve as early warning signs for impending financial restatements (SEC Form 8-K Item 4.02). By constructing a novel, leakage-controlled dataset of 198 transcripts, we analyze the structural differences between scripted prepared remarks and unscripted analyst Q&A. Contrary to hypotheses emphasizing unscripted evasion, our findings demonstrate that executives overcompensate with highly manufactured, optimistic language in their prepared remarks prior to restatements. Evaluating across classical lexicons, fine-tuned transformers, and large language models (LLMs), we show that scaled, general-purpose LLMs (Llama 3 70B) drastically outperform domain-adapted models in detecting these deceptive signals. Ultimately, we provide a proactive screening framework for regulatory bodies and auditors to triage transcripts before market harm crystallizes.
Teaser Figure
The figure below summarizes our current data curation pipeline. We first extract Item 4.02 filings from SEC bulk submissions data, then combine free earnings-call transcript corpora, segment calls into full/scripted/Q&A views, match positives in a pre-event window, and construct a 2:1 matched control set.
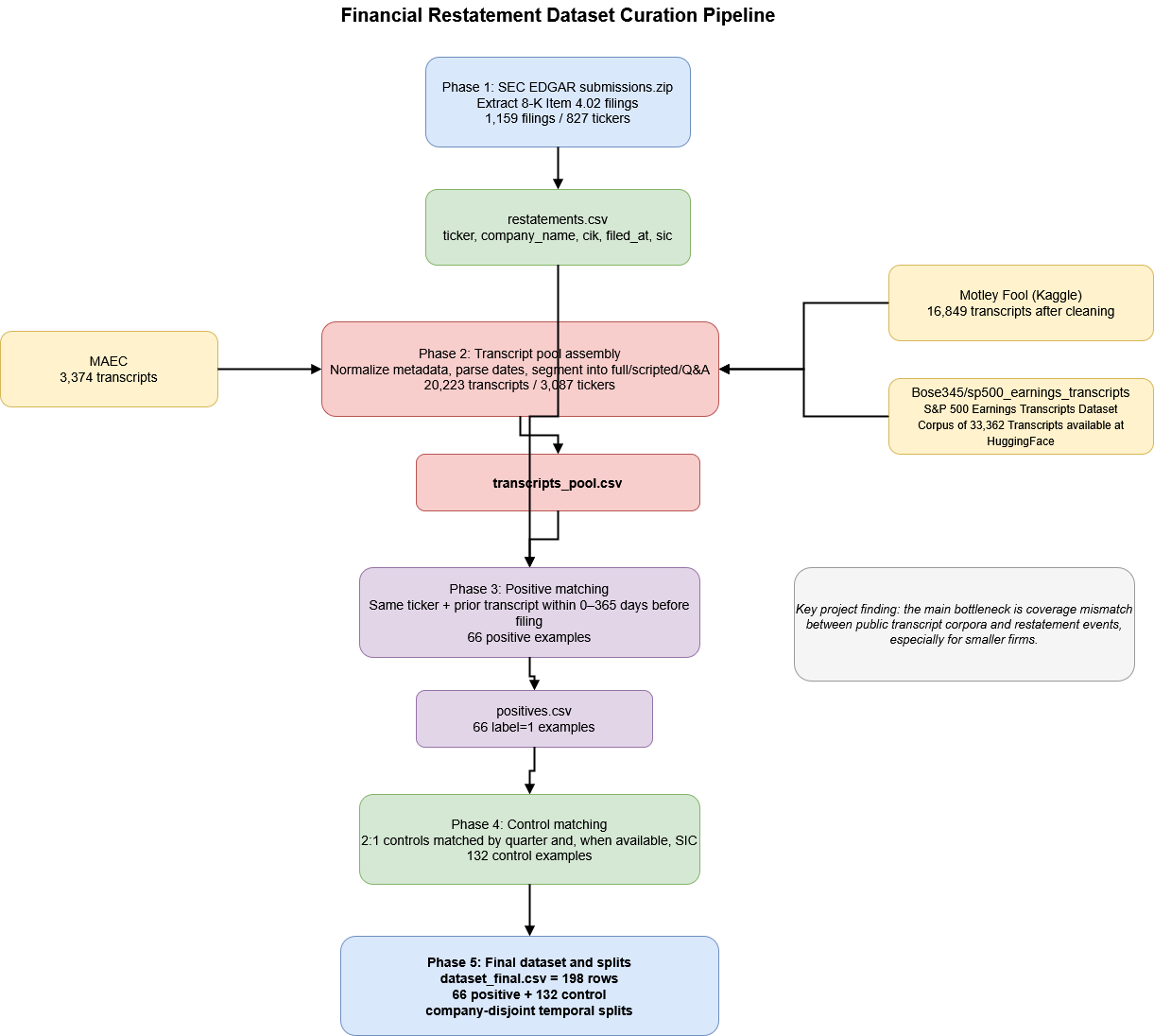
Pipeline summary
This project’s main technical milestone was the dataset pipeline. The biggest challenge was aligning regulatory events with publicly available transcript data in a leakage-aware way to prevent data contamination.
Introduction / Background / Motivation
What problem are we trying to solve?
When a publicly traded company files SEC Form 8-K Item 4.02, it formally discloses that previously issued financial statements should no longer be relied upon. We ask whether there are earlier linguistic signals in management’s earnings-call language—especially in unscripted analyst Q&A—that precede these restatement disclosures.
Why is this difficult?
Prior work on earnings calls mostly studies market outcomes such as volatility or returns, not discrete regulatory events. In our case, the core difficulty is dataset construction, because the public transcript corpora skew toward large-cap firms, while Item 4.02 restatements often occur at smaller firms with weaker controls. This creates a structural coverage mismatch between labels and available text.
Why does it matter?
If linguistic signals exist before a restatement becomes public, they could support a probabilistic screening tool for analysts, regulators, or researchers. Our aim is not to accuse firms of fraud, but to study whether language carries measurable early-warning patterns under realistic data limitations.
Approach
How is the dataset built?
- Phase 1: Restatement labels: Extract SEC Form 8-K Item 4.02 events from the SEC EDGAR submissions.zip bulk file. This yields 1,159 unique filings from 827 tickers spanning 2015–2024.
- Phase 2: Transcript pool: Load and standardize earnings call transcripts from MAEC, Motley Fool, and S&P 500 Hugging Face corpus. The current combined pool contains 20,223 transcripts from 3,087 tickers.
- Phase 3: Positive matching: Link transcripts to later Item 4.02 filings using a 0–365 day pre-event window. This yields 66 positive examples.
- Phase 4: Controls: For each positive example, sample two non-restating control calls matched on calendar quarter and, where available, SIC information.
- Phase 5: Final dataset: Assemble 198 examples total (66 positive, 132 control) and create company-disjoint temporal splits.
What changed relative to the original proposal?
Originally, we proposed a 90–180 day clean window and a target of roughly 300–500 labeled calls. In practice, public transcript coverage limited overlap with restatement events. We therefore broadened the positive matching window to 0–365 days.
Current model tiers
- Tier 1: Lexicon baseline (Loughran-McDonald, TF-IDF)
- Tier 2: Fine-Tuned Transformers (FinBERT, Longformer, BERT, RoBERTa, DistilBERT)
- Tier 3: Zero/Few Shot LLM prompting (Llama 3 8B/70B, FinGPT)
Results & Discussion
Tier 1: Lexical Baselines and the Failure of Dictionaries
The Tier 1 baseline establishes the performance ceiling of non-contextual NLP methods. We engineered a custom feature extraction pipeline utilizing a FeatureUnion to combine term frequencies across six Loughran-McDonald (LM) dictionary categories with standard TF-IDF unigrams. We evaluated Logistic Regression, Linear SVM, and Random Forest classifiers across our three structural conditions (Full, Scripted, and QA-Only).
| Condition | Model | AUROC | PR-AUC | HR-F1 |
|---|---|---|---|---|
| Full Text | Logistic Reg. | 0.631 | 0.468 | 0.550 |
| SVM (Linear) | 0.657 | 0.486 | 0.500 | |
| Random Forest | 0.591 | 0.453 | 0.571 | |
| Scripted | Logistic Reg. | 0.525 | 0.409 | 0.564 |
| SVM (Linear) | 0.530 | 0.405 | 0.435 | |
| Random Forest | 0.545 | 0.444 | 0.417 | |
| QA-Only | Logistic Reg. | 0.429 | 0.345 | 0.550 |
| SVM (Linear) | 0.455 | 0.358 | 0.333 | |
| Random Forest | 0.482 | 0.380 | 0.385 |
Surprisingly, classical financial sentiment lexicons lacked the structural nuance required for discrete regulatory event detection. While classical models achieved moderate discriminative power on the full text (SVM AUROC = 0.657) and scripted remarks (RF AUROC = 0.545), performance on the unscripted Q&A segment degraded to worse than random guessing (RF AUROC = 0.482). SHAP analysis of the QA-Only model revealed highly noisy, context-dependent top features. Conversely, for the Scripted segment, raw TF-IDF unigrams overwhelmingly drove predictions, specifically overly optimistic words like forward, potential, growing, prices. This structurally validates the existence of a highly manufactured, overly optimistic linguistic façade in the prepared remarks (our Overcompensation Hypothesis).
Tier 2: Fine-Tuned Transformers and Section-Dependent Signal Polarity
To evaluate whether contextual word representations capture subtle evasion signals missed by bag-of-words baselines, we fine-tuned six transformer architectures: FinBERT, Longformer, BERT-base, BERT-large, RoBERTa, and DistilBERT. For transcripts exceeding a model's maximum context window, we applied a tail-biased truncation strategy to explicitly preserve late-stage executive answers where linguistic evasion is theorized to peak.
| Condition | Best Default Model | AUROC | PR-AUC |
|---|---|---|---|
| Full Text | RoBERTa | 0.603 ± 0.118 | 0.513 |
| Scripted | Longformer | 0.476 ± 0.076 | 0.423 |
| QA-Only | BERT | 0.507 ± 0.151 | 0.451 |
The main Tier 2 finding is that signal polarity depends strongly on call structure. When the complete call is available, transformers consistently rank pre-restatement calls as slightly riskier than matched controls (RoBERTa AUROC = 0.603). However, in the scripted condition, the opposite pattern emerges: all six default transformer models achieved below-chance AUROC on prepared remarks.
We interpret this systematic inversion as evidence that transformers detected a scripted-language signal, but in the opposite direction from original evasion hypotheses. Prepared remarks before restatements may not appear more evasive or uncertain; instead, they appear unusually controlled, direct, positive, or polished. This further supports the Overcompensation Hypothesis. Unscripted Q&A did not yield a stable, correctly oriented evasion signal, subverting the assumption that live questioning leaks obvious hedging.
Tier 3: LLM Prompting and Overcompensation Dominance
Our final tier evaluated whether general-purpose and domain-adapted Large Language Models (LLMs) could extract complex linguistic deception through zero-shot prompting, bypassing the need for task-specific fine-tuning. We evaluated Llama 3 (8B and 70B) against FinGPT using strict JSON output schemas.
| Model | Condition | Parse Rate | AUROC | PR-AUC |
|---|---|---|---|---|
| Llama 3 (8B) | Scripted | 1.000 | 0.545 | 0.436 |
| QA-Only | 1.000 | 0.500 | 0.379 | |
| Llama 3 (70B) | Scripted | 1.000 | 0.611 | 0.477 |
| QA-Only | 1.000 | 0.581 | 0.422 | |
| FinGPT (13B) | Scripted | 0.034 | N/A | N/A |
| QA-Only | 0.034 | N/A | N/A |
Domain-adapted models like FinGPT suffered catastrophic degradation. Because its underlying LoRA was narrowly fine-tuned strictly for ternary sentiment classification, it failed to generalize to complex epistemic reasoning, resulting in a valid JSON parse rate of just 3.4%.
Conversely, general-purpose Llama 3 models navigated the complex schema perfectly. The 70B model achieved calibrated decision boundaries, notably hitting a higher AUROC on Scripted remarks (0.611) than on the unscripted QA-Only segment (0.581). This definitively demonstrates that the highly manufactured linguistic smokescreen deployed in prepared remarks is a more statistically reliable precursor to a restatement than unscripted evasion.
Qualitative Error Analysis & Cross-Tier Comparison
To understand the boundaries of our approach, we conducted a qualitative review of systematic misclassifications. The most prominent source of false positives across tiers was the inability to distinguish deceptive overcompensation from authentic corporate growth. In Tier 1, TF-IDF models anchored on optimistic unigrams (e.g., growing, potential) but failed to contextualize them.
In Tier 2, fine-tuned transformers failed to bridge this contextual gap due to data starvation. Attempting to fine-tune 110M+ parameter architectures on a training split containing roughly 45 positive examples forced the models into brittle, localized minima, causing the inverted signal observed in the scripted remarks.
Tier 3's Llama 3 70B overcame this data constraint by leveraging massive pre-trained world knowledge. However, false negatives predominantly occurred in the Q&A segment when executives employed "filibustering" tactics—masking misreporting by reciting dense accounting policies or pivoting to macroeconomic trends. Without the numerical grounding to cross-reference the executive's response against the analyst's underlying question, the LLM often parsed these structurally coherent, jargon-heavy deflections as factual.
Conclusion, Limitations, and Ethical Considerations
Limitations
The primary bottleneck is the dataset coverage gap. Public transcript resources underrepresent the smaller firms that disproportionately appear in the restatement set. This reduced our final matched dataset to 66 positives, which necessitates wide confidence intervals and limits our ability to make strong end-to-end transformer fine-tuning claims. Additionally, our architectural evaluations revealed that narrowly fine-tuned finance models (FinGPT) completely degrade when asked to perform complex zero-shot reasoning.
Ethical Considerations
Detecting linguistic precursors to financial restatements carries inherent risks, primarily reputational harm and market manipulation from false positives. Flagging a compliant firm's transcript for "overcompensation" could unfairly erode investor trust. Consequently, any system built upon this research must be strictly framed as a probabilistic screening aid, not an automated arbiter of truth. A "human-in-the-loop" is strictly required. In the future, we will release our findings in aggregate and offer our dataset as a community resource for academic NLP research, void of actionable trading strategies.
Conclusion & Broader Impact
By explicitly modeling the structural boundary between scripted remarks and unscripted Q&A, we subverted the initial assumption that the cognitive load of live questioning produces the strongest evasion signal. Instead, empirical results validate the Overcompensation Hypothesis: executives deploy prepared remarks as a highly manufactured, optimistic smokescreen. This framework empowers regulatory bodies and external auditors to efficiently triage thousands of earnings transcripts, flagging anomalous corporate optimism before severe investor harm crystallizes.
Future Work & Reproducibility
Future research should address the coverage gap by targeting small-cap transcripts and incorporating multimodal architectures to analyze acoustic features (e.g., vocal pitch, hesitation markers) during live Q&A. Additionally, exploring retrieval-augmented generation (RAG) to provide LLMs with historical, firm-specific baselines could drastically reduce false positives. To ensure full replicability, our anonymized dataset, segmentation scripts, LLM prompts, and modeling code will be open-sourced via our project GitHub repository upon publication.